Abstract
Method Overview
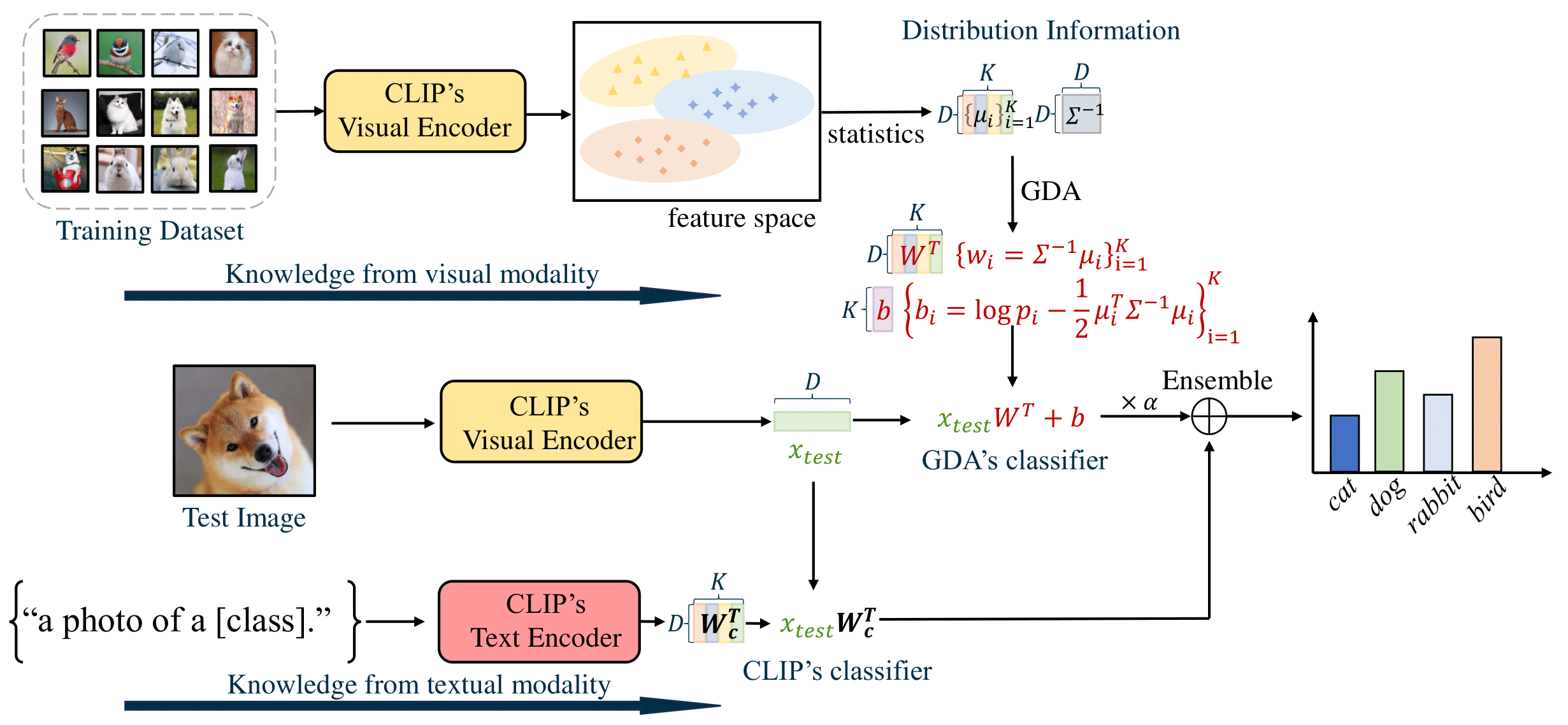
Figure 1. The overview of our training-free method. In our method, we begin by extracting visual features from the training dataset using the CLIP visual encoder. Next, we compute the mean vectors for each class and the shared precision matrix (inverse covariance) using Eq.(\ref{eq:precisionmatrix}). Through the Gaussian Discriminate Analysis (GDA), the weight and bias of the classifier can be expressed in terms of the mean vectors and the precision matrix, which can be derived from Eq.(\ref{eq:solution}) (the red formula in the figure.) Finally, we enhance our method by ensembling the GDA classifier and the CLIP's zero-shot classifier, integrating the knowledge from visual and textual modalities.
TL;DR
In this paper, we've revisited Gaussian Discriminate Analysis (GDA) within CLIP and found that it stands out as a hard-to-beat training-free baseline for CLIP-based adaptation, which surpasses previous state-of-the-art training-based and traing-free fine-tuning methods, thanks to its covariance assumption. Moreover, we have expanded its application to include CLIP long-tail classification, base-to-new generalization, and unsupervised learning, showcasing its broad effectiveness.
Basic Setting
Gaussian Dicriminate Analysis (GDA) is a well-known probability discriminative method in machine learning. Without explicit learning such as gradient descent, GDA obtains the classifier by estimating the mean vectors and the covariance matrix of the data. By utilizing the Bayes Formula, we can obtain the classification weights as follows:
We can further ensemble GDA with the CLIP zero-shot classifier.
We apply this formula in CLIP few-shot classification and long-tailed classification.
Extention to more scenarios
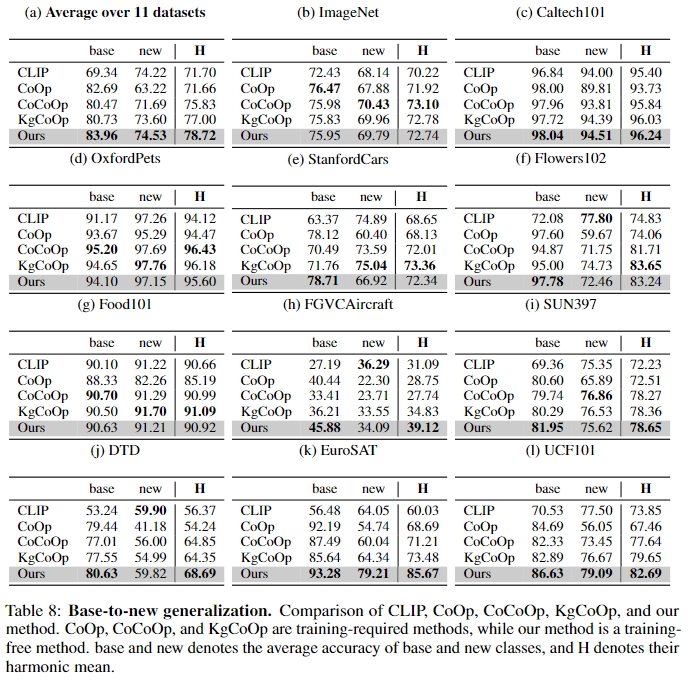
Base-to-New Generalization
Unsupervised Learning
In the unsupervised learning scenario, we only have the unlabeled data \(\{x_i\}_{i=1}^N\). Based on the Gaussian assumption in GDA, the unsupervised data \(\{x_i\}_{i=1}^N\) follow Gaussian mixture distribution. In order to maintain the simplicity of our method, we directly employ the EM algorithm for estimating the means and covariance matrix. To begin, we initialize the mean vectors and covariance using the zero-shot classifier, assuming equal priors for each Gaussian distribution. In the E-step, we calculate the probability of the unlabeled data \(\{x_i\}_{i=1}^N\) as follows:
for the unlabeled data \(\{x_i\}_{i=1}^N\), and \(f\) is the logit function using Eq.(\ref{eq:ensemble}). Moving on to the M-step, we update the mean vectors and covariance matrix using the following formulas:
Subsequently, we update the classifier using Eq.(\ref{eq:solution}) and repeat the EM process until convergence.
Experiments
Few-shot Classification
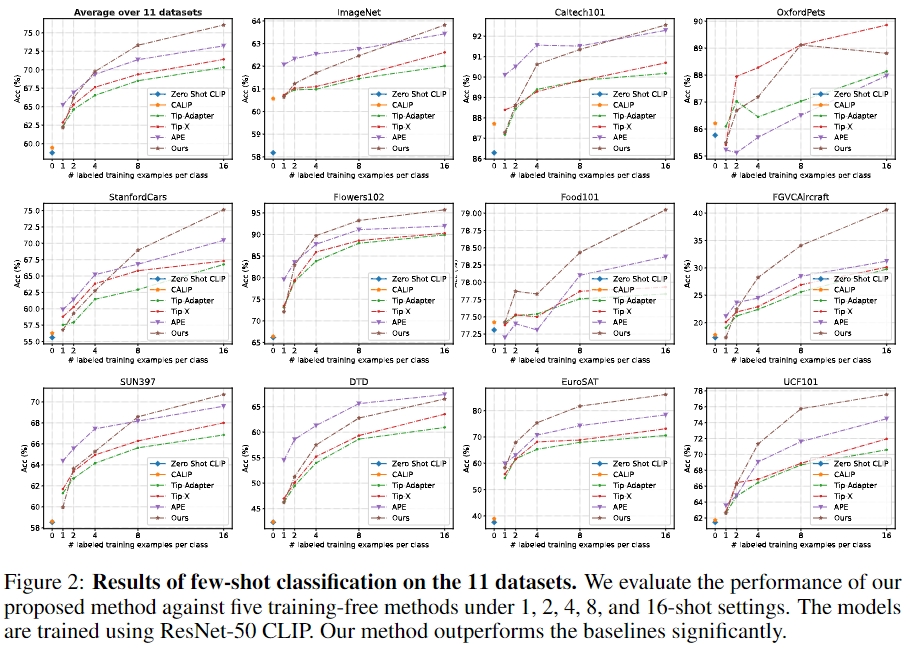
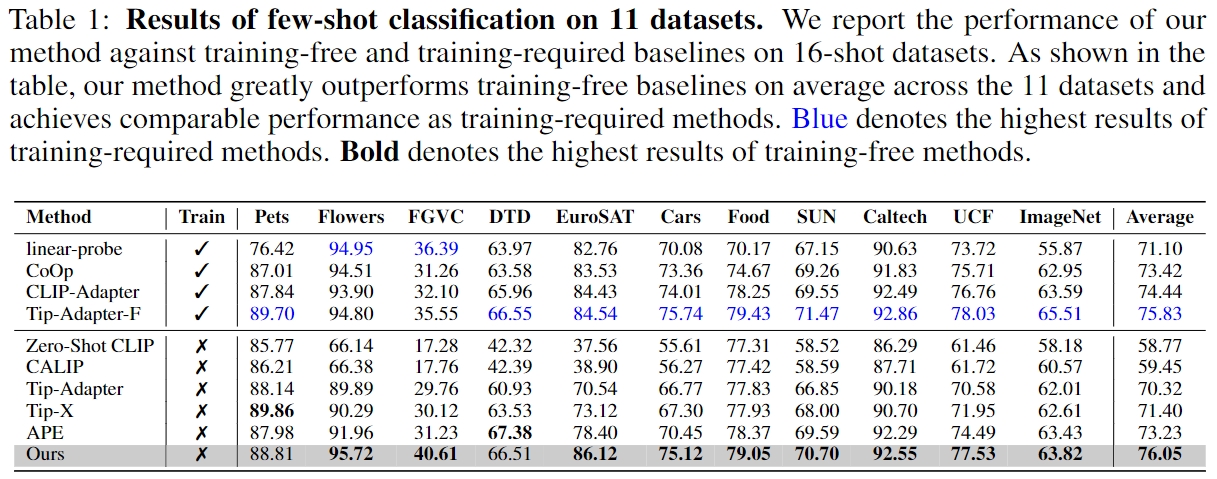
Base-to-New Generalization
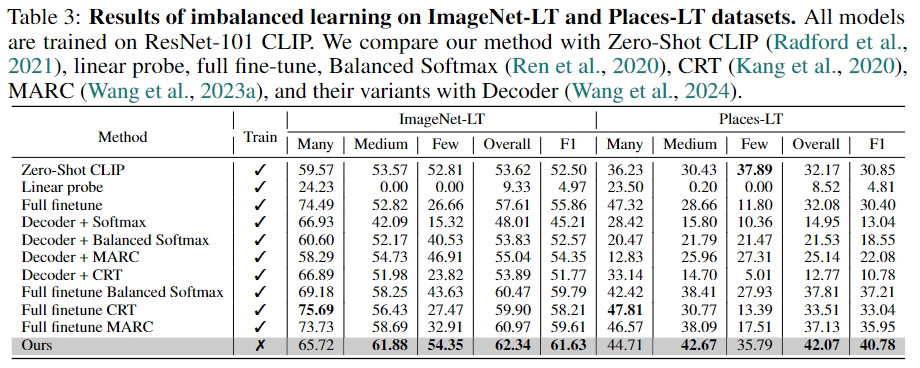
Long-tailed Classification
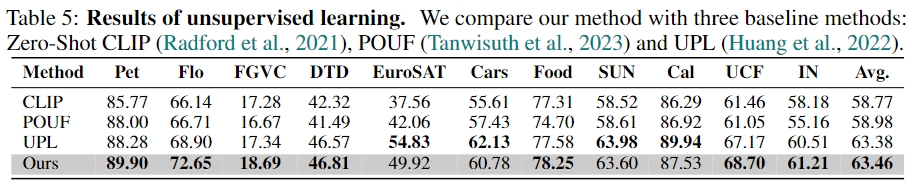
Unsupervised Learning
BibTeX
@article{wang2024baseline,
author = {Wang, Zhengbo and Liang, Jian and Sheng, Lijun and He, Ran and Wang, Zilei and Tan, Tieniu},
title = {A Hard-to-Beat Baseline for Training-free CLIP-based Adaptation},
journal = {The Twelfth International Conference on Learning Representations (ICLR)},
year = {2024},
}